




Relationen mellan översättare och projektledare – hur ser den ut?...
När den frilansande översättaren (eller granskaren) i sin yrkesvardag har kontakt med byråer sker det...
13 feb, 2026Det finns både fördelar och nackdelar med att ta AI till hjälp vid översättning, särskilt facköversättning. AI kan också användas till annat än själva översättningen.
Artikelförfattaren gick igenom detta på SFÖ-SAT:s konferens i Uppsala våren 2024.
 Illustration: Gidon Avraham, Linguistrator AB
Illustration: Gidon Avraham, Linguistrator AB
Generativ AI – alltså AI som själv ”skapar”, i detta fall text, till skillnad från ”vanlig” MT som mer strikt utgår från tidigare översättningar – kan användas för översättning genom att man går till en motsvarande tjänst, typiskt ChatGPT eller Gemini, och ber tjänsten översätta den text som man lägger in. Man kan samtidigt ge anvisningar (”prompter”) såsom att måltexten ska vara anpassad till en allmän läsekrets eller till en expertpublik.
Men sådana översättningar handlar alltså om att man matar in källtexten i dess helhet och får en motsvarande måltext. Vi facköversättare jobbar i allmänhet inte så; vi använder ju oftast CAT-verktyg där vi översätter ett ”segment” i taget, eventuellt med hjälp av MT. Nu kan vi alltså utvidga begreppet MT till att även omfatta AI, även om det för närvarande erbjuds mycket få alternativ: memoQ ”samarbetar” med Alexa Translations och håller dessutom på att utveckla sin egen tjänst memoQ AGT; Trados Studio erbjuder framför allt OpenAI ChatGPT och Microsoft Azure (men även vissa andra) via s.k. insticksprogram (plugins) – se del II av denna presentation. Matecat har en AI Assistant som jag inte känner närmare till. Och förmodligen finns även andra motsvarande tjänster för andra CAT-verktyg. Men överlag är detta i sin linda, både vad gäller utbudet av tjänster och deras kvalitet. Vi har säkerligen en spännade utveckling att se fram emot (eller frukta).
Vidare har vi två användningar där AI kan bidra precis som ”vanlig” MT redan gör, men möjligen mer/bättre/annorlunda:
Jag har redan nämnt möjligheten till upprepad förbättring av måltexten m.h.a. väl formulerade prompter. (Exempelvis tänker jag mig att det ibland kan vara enklare att i klartext formulera en viss, genomgående förändring i en prompt än med motsvarande s.k. regular expressions.)
En odiskutabel fördel är vidare att AI är bättre på grammatik än MT. Det gäller särskilt böjningsformer (adjektiv, verb, ändelser). Sålunda kan ett byte av exempelvis ett maskulint substantiv mot ett feminint med hjälp av AI innebära att en tillhörande bestämning automatiskt får rätt böjning.
Vidare kan möjligheten till översättning av hela dokument medföra större enhetlighet genom hela måltexten. Men det är förstås svårt att genomföra när man använder AI via CAT-verktyg.
Nackdelarna är som bekant många (och delvis förstås desamma som vid traditionell MT-översättning).
Jag tror dock att flera av de här nackdelarna kommer att hanteras bättre i och med att tekniken utvecklas och dataunderlagen blir större.
Men apropå större dataunderlag: det har talats en del om att AI-tjänsterna, som utvecklas med hjälp av kolossala datamängder, snart kommer att få slut på underlagsdata och därför inte kommer att utvecklas lika snabbt i framtiden. OpenAI:s vd Sam Altman menar dock att detta är överdrivet; det handlar mer om att förbättra tekniken än att dammsuga nätet på mer data. Ett mer verkligt problem, som även Altman pekar på, är att användningen av AI kommer att kräva allt mer energi, både för träning av tjänsterna och för deras användning (inte minst för kylning). Sålunda uppskattar IEA att datacentralerna redan om två år kan komma att sluka dubbelt så mycket energi som i dag och stå för en tredjedel av all efterfrågan på ny elektricitet i USA. Där har vi en nackdel som heter duga!
I princip kan samma sak gälla för sekretess/konfidentialitet vid användning av AI-tjänster som vid användning av övriga MT-tjänster: En gratistjänst ger ingen sekretess. En betald tjänst där man har ett eget konto: leverantören garanterar däremot i allmänhet sekretess, dvs materialet används inte för att ”lära upp” tjänsten och sparas heller inte. Exempelvis sägs för Microsofts Azure OpenAI att “Your prompts (inputs) and completions (outputs), your embeddings, and your training data are NOT available to other customers, are NOT available to OpenAI, are NOT used to improve OpenAI models”.
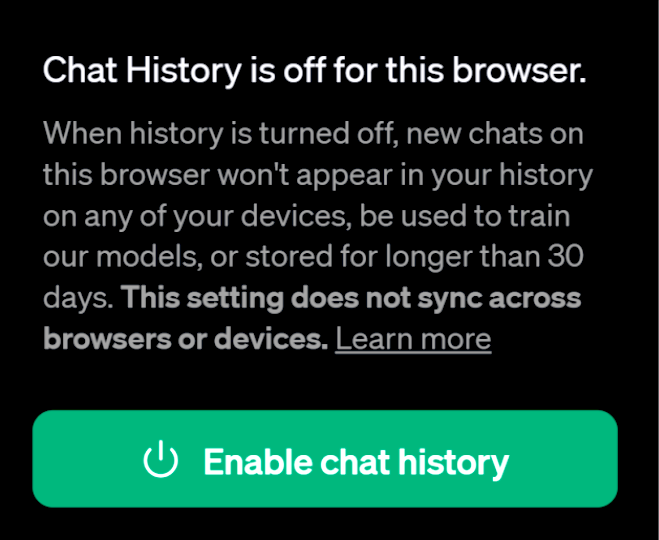
Men obs! ”i allmänhet” innebär tyvärr att man kan behöva kolla. Sålunda visar det sig för ChatGPT (den mest använda/erbjudna tjänsten) att man även med inloggning på eget konto själv måste välja att inte låta OpenAI använda chatt-historiken – se bilden ovan.
Användningen av AI hos bokförlag är intressant även för SFÖ-SAT av två skäl: Dels är det många medlemmar som då och då översätter böcker; dels sker utvecklingen inte isolerat och vi kan lära oss av det som händer på förlagssidan.
Det finns redan några förlag som använder AI-översättningar som sedan bearbetas av ”riktiga” (?) översättare. Det gäller främst, säger man, genrelitteratur av typen romans, spänningslitteratur och liknande (mer schablonmässiga?) texter. Och det finns alltså översättare som ställer upp på detta. Men de erfarenheter vi har hört talas om är inte positiva. Den tyska översättaren Miriam Neidhardts redogörelse i Översättarcentrums tidskrift Med andra ord nr 115 (juni 2023) är intressant även om AI-tjänsten i fråga inte var AI utan DeepL.

Och här har vi en helt AI-genererad barnbok – text och bild – nämligen Trisse Traktor. Läs mer om detta fenomen i den här DN-artikeln.
Det kan förstås hänga samman med att grundtjänsten “ChatGPT” är gratis. För ChatGPT Team, som kostar $25/månad, säger OpenAI däremot att ”We do not train on your business data” och ”You own your inputs and outputs”. Alltså olika (och rörigt), så det är värt att kolla upp. (Exempelvis Amazon AI säger uttryckligen att de kan komma att lagra användarens innehåll för att förbättra tjänsten även om denne har valt att inte låta lagra innehållet för det syftet!)
I en färsk undersökning gjord av brittiska Society of Authors (SoA) – som även organiserar översättare – redovisas en del oroande tendenser och farhågor. Det rör sig visserligen om förlagsvärlden, men tendenserna berör säkerligen även facköversättarna.
Sålunda visar det sig bl.a. att
Undersökningen redovisas här, och en kommenterande artikel i The Guardian ger en del ytterligare intressanta synpunkter.
Se för övrigt den SFÖ-SAT-enkät som Örjan Skoglösa presenterade på konferensen och som finns eller kommer att finnas på denna webbplats.
EUs nyligen antagna Artificial Intelligence Act (huvuddelen av titeln på svenska lyder “Europaparlamentets och rådets förordning om harmoniserade regler för artificiell intelligens”) är på ca 450 sidor och handlar framför allt om hantering av de risker som utvecklingen och användningen av AI kan medföra. Den förefaller inte påverka vårt arbete men kanske allas vår framtida tillvaro. (Här finns en kort sammanfattning.)
Av betydligt större intresse för oss är ATA Statement on Artificial Intelligence. ATA står för American Translators Association och är således en systerorganisation till oss. Och även om man också organiserar boköversättare är detta uttalande av klart intresse för oss; jag föreslår att SFÖ-SAT tar en titt för att sedan göra ett motsvarande uttalande. Så här lyder slutklämmen:
”Moving forward, the Association will explore other aspects of AI-based tools and how the profession is adapting to them, with the goal of providing insights, ideas, and solutions.”
När den frilansande översättaren (eller granskaren) i sin yrkesvardag har kontakt med byråer sker det...
13 feb, 2026
” Översättning och AI – Vad är problemet?”
22 dec, 2025
Vad har 1800-talets ludditer att säga 2000-talets facköversättare? Mer än du tror!
8 nov, 2025 ►
► Översättare har blivit språkhandläggare
27 okt, 2025
Vilka yrken ligger i farozonen? Läs om Almegas nya rapport och om översättare och tolkars spådda yrk...
8 maj, 2025
Vad är ChatGPT och generativ AI? Är ChatGPT bara ytterligare ett verktyg i verktygslådan?
17 sep, 2023
Hur såg Hieronymus på översättande? Och var det egentligen ett äpple som Eva åt?
22 okt, 2023

Välbesökt minikonferens i SFÖ-SAT:s regi
13 dec, 2023
Brittisk whodunnit och svenskt höstrusk.
6 feb, 2023
Lägesbeskrivning och framtidsspaning: ”Tolkning och AI – vilka frågor behöver vi ställa?”
28 okt, 2023
Årets upplaga av Nordic Translation & Interpretation Forum (NTIF) i Malmö
8 dec, 2022
Dags att bygga stora svenska språkmodeller att ”mata” AI med – men hur?
12 jun, 2024
Minneskavalkad från föreningens historia
3 mar, 2025
En facköversättare är nyfiken på hur en skönlitterär översättare arbetar
12 mar, 2025
Är den enskilde översättaren oersättlig? Eller helt utbytbar?
30 apr, 2025
En facköversättare i samtal med en bibelöversättare
22 maj, 2024
Den amerikanska föreningen för översättare och tolkar, ATA, höll i oktober 2022 sin årliga konfe...
19 jan, 2023
En översatt text är alltid något annat än originalet
10 maj, 2022
Har du läst din patientjournal någon gång? Förstod du någonting eller var det rena grekiskan?
20 maj, 2025
Översättare (engelska/tyska/franska/danska/norska till svenska inom främst naturvetenskap, ekonomi, teknik, samhällsvetenskap; även skönlitteratur), skribent och redaktör. Auktoriserad av Kammarkollegiet för engelska till svenska. Utger sedan 2012 handboken Trados Studio Manual.

Kan verkligen översättning standardiseras? Nej, översättning kan förstås inte standardiseras. Ändå fi...
6 mar, 2026
Vad som i förstone kan verka vara ett enkelt svar på rubrikens fråga visar sig vid närmare bet...
26 jan, 2026
Varje vår händer det. Simsalabim, nu blir det konferens för SFÖ-SAT igen! Men hur går det till? Hur gör man så att evenem...
17 mar, 2026
Högtidsdag för språkintresserade
10 mar, 2026
Dags att söka översättarpraktik på EU:s ministerråd!
1 feb, 2026
Poesin uppstår och poesin smeker
23 jan, 2026
Lektörer sökes
17 jan, 2026
Lägesrapport från föreningsstyrelsen i SFÖ-SAT
15 jan, 2026
Tolken blir totalcharmad – och undrar om det går för sig
14 jan, 2026
Bredden i den svenska bokutgivningen hotad
16 dec, 2025
Språkmuseets popup invigs med bubbel, klang och jubel på Kulturhuset i Stockholm
13 nov, 2025
På gång just nu: Översyn av auktorisationsproven, eventuella förändringar vid tolkning på häktet med mera
12 nov, 2025
Hur fungerar vårt mänskliga minne, och på vilket sätt avspeglar det sig i polisförhör som sker med hjälp av tolk?...
16 okt, 2025
Att känna sig som en bluff fast man fått Nobelpriset låter kanske otroligt märkligt.
26 sep, 2025
Vässa din profil som översättare – det är enklare än du tror!
25 sep, 2025
Sök praktik som översättare hos EU:s ministerråd!
11 sep, 2025
Vad innebär den senare tidens utveckling på översättarområdet? Kan vi utnyttja den till vår fördel?
9 sep, 2025