

Verktygstipset
Planeringsverktyg kan hjälpa frilansare att inte tappa någon av sina bollar
23 apr, 2024
Planeringsverktyg kan hjälpa frilansare att inte tappa någon av sina bollar
23 apr, 2024
Selma Lagerlöf lär oss om konferensstaden Uppsala, och bakar en smarrig moralkaka.
26 mar, 2024
Gärna internationalisering – men bara med engelska
22 mar, 2024
Med Engelbrekt och Jesus som revolutionära ideal
8 mar, 2024
eV tar pulsen på de medverkande vid SFÖ-SAT:s konferens i Uppsala den 19–20 april.
6 mar, 2024
Inför SFÖ-SAT-konferensen i Uppsala den 19–20 april ställer eV några frågor till de medlemmar som ska...
28 feb, 2024
En blixtbild från i höstas av AI-översättning jämfört med välrenommerad MT-översättning.
26 feb, 2024
Inför SFÖ-SAT-konferensen i Uppsala den 19–20 april ställer eV några frågor till de medlemmar som ska...
22 feb, 2024
Årets konferensstad Uppsala är ju bäst – eller?
16 feb, 2024
Mot en kvalitetssäkrad auktorisationsprocess
15 feb, 2024
Inför SFÖ-SAT-konferensen i Uppsala den 19–20 april ställer eV några frågor till de medlemmar som ska...
14 feb, 2024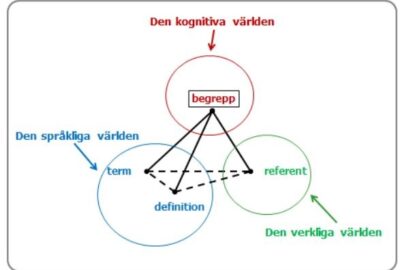
Nu lanseras Terminologifrämjandets konsultlista
8 feb, 2024
MTPE – så mycket mer än bara språktvätt
2 feb, 2024
Bok om översättaryrket på 2020-talet fyller lucka
1 feb, 2024
Funderingar kring inre dialog och källspråkets specifika vikt.
1 feb, 2024
Danskt-norskt-finskt-svenskt-isländskt-grönländskt seminarium
18 jan, 2024
Lägesrapport från föreningsstyrelsen i SFÖ-SAT
22 dec, 2023
Välbesökt minikonferens i SFÖ-SAT:s regi
13 dec, 2023
Välbesökt översättar- och tolkkonferens med bredd
6 dec, 2023
Konferens i Baltikum – satsa på att bli en LangOps, men undertexta inte med AI
23 nov, 2023
SFÖ-SAT ordnar minikonferens om AI – möt arrangören Natalia Walawender!
13 nov, 2023
Lägesbeskrivning och framtidsspaning: ”Tolkning och AI – vilka frågor behöver vi ställa?”
28 okt, 2023
Är framtidens tolk en talande avatar?
28 okt, 2023
Hur såg Hieronymus på översättande? Och var det egentligen ett äpple som Eva åt?
22 okt, 2023
Språkquiz, pingis, minnen från SFÖ:s grundande, föredrag om högaktuellt ämne och mycket annat
19 okt, 2023
Värdefulla tankar för våra uppdragsgivare – men även för oss tolkar och översättare – i 2:a upplagan!...
12 okt, 2023

Brittisk whodunnit och svenskt höstrusk.
6 feb, 2023
I många språkkombinationer saknas bra lexikon. Vilka konsekvenser får detta för översättaren och målt...
25 nov, 2022
Julpantomim, julmust - och nya krafter i SFÖ
22 dec, 2022
Från jurist till översättare – Noggrannhet och språkkänsla gemensamt krav för båda yrkena
1 sep, 2023

Läs våra berättelser om saker värda att minnas (om du var där) eller få reda på (om du missade evente...
30 nov, 2022
Årets upplaga av Nordic Translation & Interpretation Forum (NTIF) i Malmö
8 dec, 2022 Sponsrat av Maria Bertilsson
Sponsrat av Maria Bertilsson Tips om skrivarkurs
30 dec, 2022
Snoken och huggormen
28 feb, 2023
Det var lokalisering som fick mig att lämna journalistiken för översättning.
16 aug, 2023

Mitt råd till arrangörerna är att snarast makulera den svenska upplagan av utställningskatalogen, skr...
8 sep, 2023
En översatt text är alltid något annat än originalet
10 maj, 2022
Viktigt att navigera mellan högt och lågt i mediebruset
1 okt, 2022
En facköversättare ger sig på dramatiköversättning
15 nov, 2022
Träff för översättare och tolkar i Umeå gav mersmak
2 apr, 2024
Lyssna på nästan 50 språk på ny webbsida
6 mar, 2024
”Författarens röst i texten försvann”
21 dec, 2023
Kvalité, arvoden och utbildning fokusområden för nordiskt-baltiskt nätverk
6 dec, 2023
Utredning: använd auktoriserad tolk och översättare i migrationsärenden
28 okt, 2023
Ukrainskt Ї som motståndshandling
12 okt, 2023
Språkbad i Östersjöns absoluta centrum
28 sep, 2023
Hieronymus anses som bekant vara översättarnas skyddshelgon. Om han faktiskt blev helgonförklarad är däremot okla...
21 sep, 2023
Välkommen till UX-skribentens hemliga värld
19 sep, 2023
Vad är ChatGPT och generativ AI? Är ChatGPT bara ytterligare ett verktyg i verktygslådan?
17 sep, 2023
Välkomna till den här terminens seminarier på Språkrådet
15 sep, 2023
Nu är det dags att lämna in ansökan om praktik februari–juli 2024 på ministerrådets svenska översättningsenhet i Bryssel!...
13 sep, 2023
Nu kan vi äntligen meddela att nästa års SFÖ-SAT-konferens kommer att hållas i Uppsala den 19–20 april 2024!
12 sep, 2023
För andra gången fick SFÖ, i år med förstärkning av våra kollegor på tolksidan.
11 sep, 2023
En glad nyhet är att vi kunde fatta beslut om att genomföra en SFÖ-SAT-konferens 2024!
11 sep, 2023